




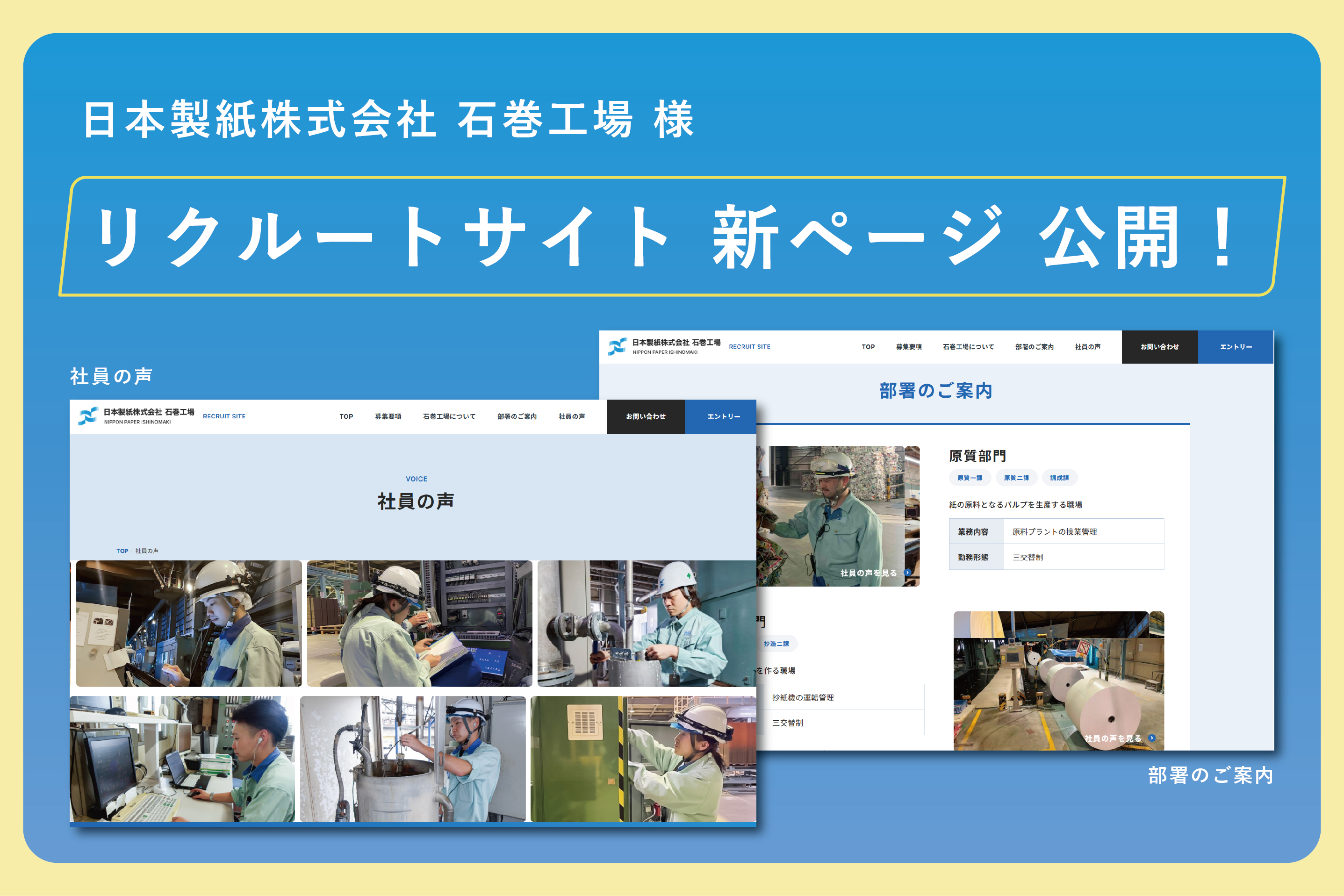
STAFF BLOGスタッフブログ
【MISA研修報告】「Pythonデータ分析実践」を受講しました。

こんにちは、シャトルです。
今回は、Pythonの研修報告となります。これまで、Pythonに全く触れたことのない初学者がPythonを通しどのようにデータ分析をするのかを学びました。その内容を簡単にまとめましたので、興味のある方は覗いてくれたら嬉しいです。
※今回はデータ分析におけるPythonの基礎に触れています。研修は受けましたが、当技術への認識/理解に誤りがある場合はありますので、予めご了承ください。
研修受講に至ったきっかけ
まず、受講を決めるにあたって、業務に活用、反映できそうな技術やツールかどうかを判断し、その中でどのような知見や経験、成果物が得られるのかを想像した上で最適な研修を選択しました。
具体的になぜこの研修かというと、WEBサイト上のデータ活用/分析に使えそうだったからです。アド・エータイプのWEBサイト制作では作成して終わりではなく、公開した後にユーザーのアクセスや行動等を分析し、それに沿ったサイト改善やリニューアルを提案しています。ぼんやりとですが、そのフロー(レポート作成やデータ分析)の中にPythonが活用できると考えました。
「Pythonデータ分析実践」の研修内容について
研修カリキュラムですが、全6回で、ざっくりと以下のような内容です。
- ① pandas、Matplotlib、seabornライブラリを使用したデータ分析
(データ読み込み、確認、加工、可視化) - ② scikit-learnライブラリを使用した分類(データのカテゴリ予測)モデル構築
- ③ 分類&回帰(データの値予測)モデル構築①
- ④ 分類&回帰モデル構築②
- ⑤ 最終発表会に向けた準備、資料作成
(どんなテーマにするか、分析をもとに何が解決、提案できるかを模索) - ⑥ 集合研修にて最終発表会(これまでの研修をもとに、テーマに基づいたデータ分析発表)
流れとして、前半にpython上でデータを扱うためのライブラリ(pandasやMatplotlib、seabornなど)に触れ、データの読み込みから可視化までを行いました。中盤から後半にかけては、pythonの機械学習ライブラリであるscikit-learnを使用し、分類や回帰などの簡単なモデルを構築しました。また、モデルの精度を上げるために、特徴量の設定とその調整、モデル変更などにも触れていました。
最後には、集合研修にてそれぞれテーマに沿ったデータ分析を行うため、分析課題の調査からデータ収集、モデルを用いたデータ分析を行いました。
モデル…データからパターンや規則を学習し、予測や判断を行うための仕組みのこと
分類…データが分類されるジャンル、カテゴリを予測すること
回帰…データをもとに、新たな出力に対しその結果を予測すること
研修を受けてみての感想
研修を通して、pythonのハードルが下がったと感じました。以前のイメージではpythonと聞くと、「機械学習」・「AI」というワードが浮かび、学問的で専門性の高い分野だと考えていましたが、豊富なライブラリのおかげでより身近なものだと認識しました。さらに昨今だと、chatGPT等のAIツールの活用/連携により、もっと簡単に扱えるものになったと思います。
ただ一方で、pythonにおけるデータ分析の奥深さも知ったというのが、正直なところです。特に、分析を始める前のデータ収集やモデルに対しての特徴量の設定など、データ分析を始めるための下準備が一番重要であり、その土台がしっかりしていないと、分析結果に大きな差が生まれることも学びました。
また、グループワークがメインの研修体制であったことから、他の研修参加者の方との交流が多くあり、その中で様々な情報共有ができたことも良かったです。今後もこのような場がありましたら、是非参加してみたいと思います。
【番外編】Pythonを使用し、GA4データを取得&出力させてみた
番外編となりますが、せっかくなのでGA4のデータをpython上で処理して出力させてみたいと思います。
準備として…
公式のクイックスタートに則って、APIとアナリティクスの設定をします。
- ① Google Analytics Data APIを有効にする
- ② GA4のプロパティにサービスアカウントを追加する
※サービスアカウントは保存した認証ファイルのclient_emailの値を確認ください。
プロパティの新規追加の際には、「閲覧者」以上の権限を付与するように気を付けてください。
【1年間の月別総ユーザー数の推移】
コードはこちらです。(google colaboratoryで実装しました。)
# ライブラリのインストール
!pip install google-analytics-data pandas matplotlib
from google.analytics.data_v1beta import BetaAnalyticsDataClient
from google.analytics.data_v1beta.types import RunReportRequest
import pandas as pd
import matplotlib.pyplot as plt
# 認証ファイルのパスを指定
KEY_PATH = "/content/○○○○.json"
# GA4のプロパティIDを指定
PROPERTY_ID = "○○○○○○○○"
# クライアントの初期化
client = BetaAnalyticsDataClient.from_service_account_file(KEY_PATH)
# APIリクエストの設定(過去1年分のデータを取得)
request = RunReportRequest(
property=f"properties/{PROPERTY_ID}",
dimensions=[{"name": "date"}],
metrics=[{"name": "totalUsers"}],
date_ranges=[{"start_date": "2023-10-01", "end_date": "2024-09-30"}]
)
# データ取得
response = client.run_report(request)
# データをDataFrameに変換
data = [
{"date": row.dimension_values[0].value, "totalUsers": row.metric_values[0].value}
for row in response.rows
]
df = pd.DataFrame(data)
# データ型の変換と日付のソート
df["date"] = pd.to_datetime(df["date"])
df["totalUsers"] = df["totalUsers"].astype(int)
# 月単位で集計
df["year_month"] = df["date"].dt.to_period("M")
monthly_df = df.groupby("year_month")["totalUsers"].sum().reset_index()
# 可視化 (棒グラフ)
plt.figure(figsize=(12, 6))
plt.bar(monthly_df["year_month"].astype(str), monthly_df["totalUsers"], color='skyblue')
plt.title("Monthly Total Users (Oct 2023 - Sep 2024)")
plt.xlabel("Month")
plt.ylabel("Total Users")
plt.xticks(rotation=45)
plt.grid(axis="y")
plt.tight_layout()
plt.show()
そして、出力結果がこちらです。今回は棒グラフで描画しました。
(自社データですので、一部ぼかしを入れています。)

ユーザーだけはなく、セッションやコンバージョン関連でも扱うことができ、その指標を掛け合わせたデータも出力できるそうです。また、この内容をCSVや表計算ファイルとして作成することも可能なので、レポート作成、集計にも役立ちますね。
おわりに
以上、研修報告でした。現状、機械学習を用いたデータ分析を業務に直接活かすのは検討する必要がありますが、それ以外の分野での活用方法がいくつかあるので、会社内で意見交換しつつ、将来的には、よりクオリティの高いものにしてサービス提供できればと思います。




最近の記事RECENT POSTS




人気の記事POPULAR POSTS





カテゴリーCATEGORY




Contact usお問い合わせ
-
 会社案内ダウンロード
会社案内ダウンロード広告代理・制作のご検討されたい方へ
会社案内ダウンロード
パンフレットをご用意しております。 -
 お問い合わせ・ご相談
お問い合わせ・ご相談ホームページ制作・運用・更新についての
お問い合わせ・ご相談
ご相談やお問い合わせはこちら -
 お電話でのお問い合わせ
お電話でのお問い合わせお電話でのご相談も随時受け付けております。
お気軽にご連絡ください。 022-716-3883
平日 10:00~19:00
022-716-3883
平日 10:00~19:00